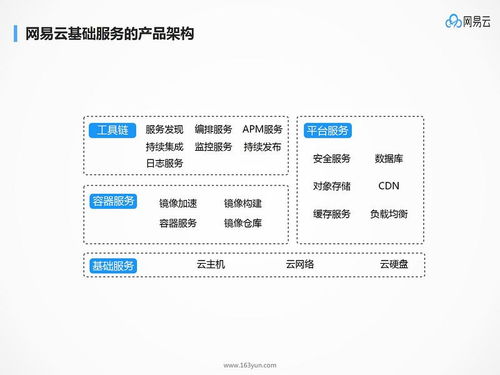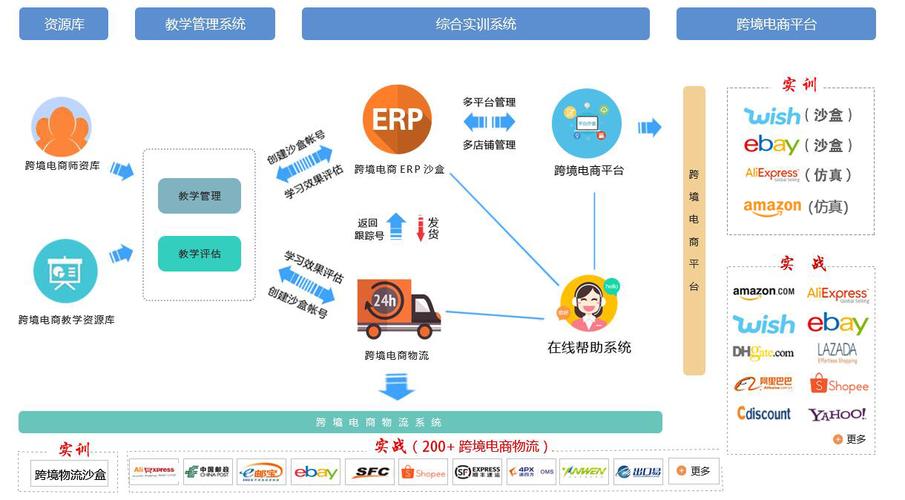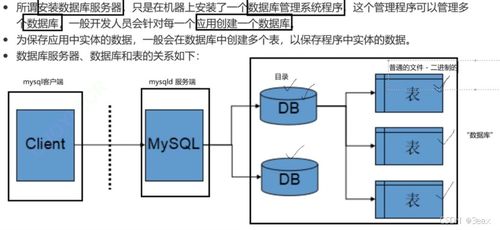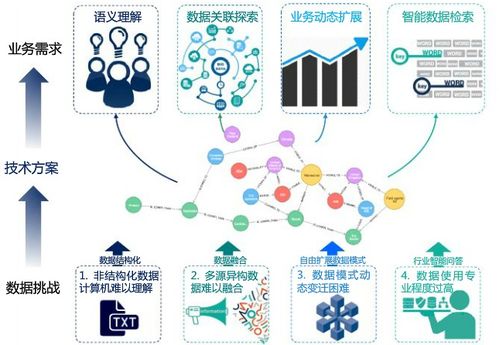
在微服务架构中,查询、数据处理和存储支持服务是实现系统高效运行的关键组成部分。它们不仅能够提升系统的可扩展性和可维护性,还能确保数据的一致性和可用性。以下将详细探讨这些服务在微服务环境中的实现方式及其重要性。
一、查询服务
查询服务负责处理用户或系统的数据请求,通常通过 API 网关或专用查询服务提供统一的入口。在微服务架构中,查询服务需要支持跨多个服务的复杂查询,常见解决方案包括:
- API 组合模式:将多个微服务的查询结果聚合,适用于简单查询场景。
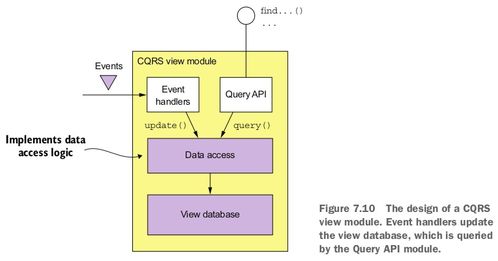
- CQRS(命令查询职责分离)模式:将读写操作分离,通过独立的查询服务处理复杂查询,提升查询性能。
- 事件溯源:通过记录事件序列来重构数据状态,支持历史查询和审计。
二、数据处理服务
数据处理服务包括数据的转换、验证、清洗和分析等功能,确保数据质量和一致性。在微服务中,数据处理通常通过事件驱动架构实现:
- 流式处理:利用 Kafka、Apache Flink 等工具实时处理数据流,支持实时分析和响应。
- 批处理:使用 Spark 或 Hadoop 进行大规模数据批量处理,适用于离线分析场景。
- 数据验证与清洗:在数据进入存储前进行格式验证和去重,防止脏数据影响系统稳定性。
三、存储支持服务
存储支持服务为微服务提供数据持久化和访问能力,需根据数据类型和访问模式选择合适的存储方案:
- 关系型数据库:适用于事务性强的场景,如 MySQL、PostgreSQL,但需注意分库分表以应对扩展性挑战。
- NoSQL 数据库:如 MongoDB(文档型)、Redis(键值型)、Cassandra(列存储),适用于高并发和灵活数据模型的需求。
- 分布式文件系统:如 HDFS 或云存储服务,用于存储大规模非结构化数据。
- 数据同步与复制:通过 CDC(变更数据捕获)或主从复制机制,确保数据在多个服务间的一致性。
四、集成与最佳实践
在微服务架构中,查询、数据处理和存储服务需要紧密集成,并遵循以下最佳实践:
- 服务解耦:通过事件驱动或消息队列(如 RabbitMQ)降低服务间的直接依赖。
- 监控与日志:使用 Prometheus、ELK 栈等工具监控数据流和存储性能,及时发现问题。
- 安全与权限:实施数据加密和基于角色的访问控制,保护敏感信息。
- 弹性设计:通过断路器、重试机制和备份策略,提升系统的容错能力。
微服务中的查询、数据处理和存储支持服务是构建高可用、可扩展系统的基石。通过合理的设计和工具选型,企业能够应对复杂业务需求,同时保障数据的高效管理和安全。