在当今大数据技术生态中,HBase作为一款高性能、高可靠、面向列的分布式NoSQL数据库,已成为企业处理海量非结构化或半结构化数据的关键技术栈。无论是数据工程师、数据开发还是大数据架构师的面试中,对HBase的深入理解往往是考察的重点。本文将从核心概念、数据处理与存储支持服务等维度,系统解析HBase的技术精髓。
一、HBase的核心定位与架构
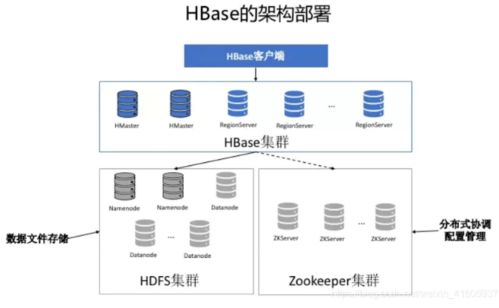
HBase构建在Hadoop HDFS之上,专为处理大规模数据集而生。它本质上是一个稀疏的、分布式、持久化的多维排序映射表,通过行键(Row Key)、列族(Column Family)、列限定符(Column Qualifier)和时间戳(Timestamp)四个维度来定位数据。其架构主要包括以下几个核心组件:
1. HMaster:负责RegionServer的负载均衡、Region的分配与迁移,以及DDL操作(如表创建、删除)。
2. RegionServer:负责具体的数据读写请求,管理多个Region。
3. Region:HBase中数据分布和负载均衡的基本单位,一个表在水平方向上被划分为一个或多个Region。
4. ZooKeeper:作为协调服务,负责维护集群状态、实现HMaster的高可用以及存储元数据位置。
这种架构确保了HBase具备线性扩展能力,能够通过简单增加机器来应对数据量和访问量的增长。
二、HBase的数据处理能力
HBase的数据处理能力是其核心价值之一,主要体现在高效的读写操作上。
- 写入优化:HBase采用LSM-Tree(日志结构合并树)作为其底层存储模型。数据首先写入内存中的MemStore,当达到一定阈值后,异步刷写到磁盘形成不可变的HFile。这种顺序写入方式极大地提升了写入吞吐量,非常适合写密集型的场景。
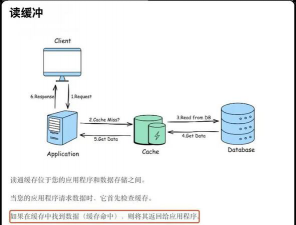
- 读取优化:读取数据时,系统会同时查询MemStore和多个HFile,并通过布隆过滤器(Bloom Filter)和块缓存(BlockCache)来加速查询。布隆过滤器可以快速判断某个数据块中是否包含目标行键,避免了不必要的磁盘I/O。
- 强一致性模型:在单个行键的维度上,HBase提供强一致性读写,所有客户端看到的同一行数据顺序是一致的。
- 丰富的API:除了传统的Put、Get、Scan、Delete操作,HBase还支持通过协处理器(Coprocessor)实现服务端计算,如自定义过滤器、聚合操作等,将计算逻辑推送到数据所在服务器,减少网络传输开销。
三、HBase的存储支持服务
HBase的强大离不开其背后稳固的存储支持服务,这确保了数据的持久性、可靠性与可管理性。
- 基于HDFS的持久化存储:HFile最终存储在HDFS上,天然继承了HDFS的高可靠、高容错特性。数据默认多副本存储,硬件故障不会导致数据丢失。
- Region的自动分片与负载均衡:随着数据增长,Region会自动分裂。HMaster会监控RegionServer的负载情况,将Region在集群内重新分布,以实现负载均衡,保证集群性能稳定。
- 数据压缩与编码:HBase支持对HFile进行多种算法(如GZ、LZO、Snappy)的压缩,以及对数据进行前缀编码、差分编码等,有效节约存储空间,提升I/O效率。
- 完善的运维与监控:HBase提供了丰富的Shell命令、Web UI以及与JMX的集成,方便管理员进行集群管理、状态监控和性能调优。其与Hadoop生态的深度集成,也使得数据导入导出(如通过Spark、Flink、Sqoop)非常便捷。
四、典型应用场景与面试要点
HBase非常适合需要随机、实时读写访问超大规模数据集的场景,例如:
- 用户画像与推荐系统:存储和快速查询用户行为、属性标签。
- 时序数据:存储物联网传感器数据、监控指标。
- 消息通信:存储在线消息、邮件数据。
- 作为大数据平台的查询结果集缓存。
在面试中,除了上述原理,候选人还需准备:
- RowKey设计原则(散列、有序、长度),这是影响性能的关键。
- HBase与RDBMS、Hive、Cassandra等的对比。
- 读写流程的详细步骤(如一次Put操作如何最终落盘)。
- Compaction(合并)机制的作用与类型(Minor/Major)。
- 如何排查和解决热点Region问题。
HBase以其卓越的扩展性、灵活的数据模型和强大的实时读写能力,在大数据存储领域占据着不可替代的地位。深入理解其数据处理逻辑和存储支持服务,不仅能帮助开发者和架构师更好地驾驭这项技术,也是在大数据面试中脱颖而出的重要筹码。