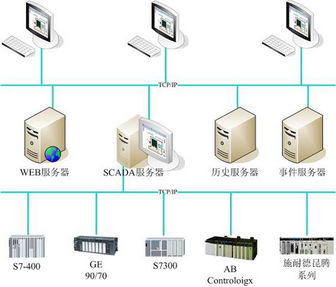
在当今数据驱动的商业环境中,如何高效地收集、存储、处理和分析海量数据,已成为企业挖掘深层价值、驱动创新与增长的核心挑战。阿里云数据湖解决方案应运而生,作为一个集成的、开放的企业级数据平台,它全面覆盖了从数据采集、存储、处理到分析与应用的全链路,旨在帮助企业打破数据孤岛,构建统一、弹性的数据底座,从而充分释放数据的内在价值。
一、 核心优势:一体化架构,全面满足数据需求
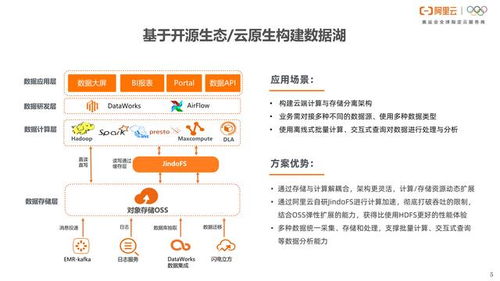
阿里云数据湖解决方案的核心在于其一体化与开放性。它并非单一产品,而是构建在阿里云对象存储OSS之上,整合了大数据计算、数据集成、数据开发、数据治理等一系列服务的完整体系。其核心优势体现在:
- 海量异构数据统一存储:基于高可靠、高扩展、低成本的对象存储OSS,方案支持结构化、半结构化和非结构化数据的原生存储,无需预先定义Schema,为企业提供了一个容纳所有原始数据的“湖”。无论是数据库日志、IoT设备流、音视频文件还是文档,都能无缝汇入。
- 全链路数据处理能力:提供了从批处理(MaxCompute)、流计算(Flink/Blink)、交互式分析(Hologres)到机器学习(PAI)的完整计算引擎。企业可以根据业务场景灵活选择计算模式,实现对热数据、温数据、冷数据的高效处理与分析。
- 开放与生态兼容:全面兼容Hadoop、Spark、Hive等开源生态,保护企业现有技术投资。提供标准化的数据访问接口(如OSS SDK、表格存储TableStore),便于各类应用和工具直接对接。
- 企业级数据治理与安全:内置完善的数据权限管理、元数据管理、数据质量监控和数据血缘追踪功能。通过DataWorks等平台,实现数据资产的可视化、开发流程的规范化与运维的自动化,保障数据在安全合规的前提下被有效利用。
二、 数据处理与存储支持服务:坚实的技术底座
阿里云为数据湖解决方案提供了强大、可靠的数据处理与存储支持服务,这是整个方案高效运转的基石:
- 存储层(OSS):提供无限容量、11个9的数据持久性,支持多种存储类型(标准、低频、归档)以优化成本。其高吞吐和低延迟特性,能满足上层计算引擎对数据高速访问的需求。
- 计算引擎服务:
- 实时计算:基于Flink的实时计算平台,支持毫秒级延迟的流数据处理,适用于实时监控、风险预警等场景。
- 大数据计算(MaxCompute):提供EB级数据的离线批量处理能力,以极低的成本完成复杂的数据清洗、转换和建模任务。
- 交互式分析:如Hologres,支持对海量数据的亚秒级多维查询与实时分析,助力商业智能与即席查询。
- 数据集成与开发(DataWorks):提供可视化的数据同步、任务调度、工作流编排和协同开发环境,极大降低数据开发与运维的门槛和复杂性。
- 智能与AI服务(PAI):集成机器学习平台,让数据科学家和业务分析师能够便捷地在数据湖上构建、训练和部署AI模型,将数据价值直接转化为智能决策。
三、 释放数据价值:驱动业务创新与增长
通过部署阿里云数据湖解决方案,企业能够实现:
- 降本增效:存算分离架构使存储与计算资源可独立弹性伸缩,避免资源浪费;统一的数据平台减少了多套系统带来的维护成本和数据迁移开销。
- 加速洞察:消除数据壁垒,使业务、分析师和数据科学家能够快速访问一致、可信的数据源,缩短从数据到洞察的时间,支持更敏捷的业务决策。
- 赋能创新:为高级分析、用户画像、精准推荐、预测性维护等数据密集型应用提供肥沃的土壤,催生新的业务模式和服务,打造核心竞争力。
- 合规与可控:完善的数据治理框架确保数据在全生命周期内的安全、质量和合规性,满足日益严格的监管要求。
###
阿里云数据湖解决方案,凭借其全面、开放、智能的特性,以及背后强大的数据处理与存储支持服务,正成为众多企业构建现代化数据架构的首选。它不仅仅是一个技术平台,更是企业将数据从成本中心转化为价值中心的战略引擎。通过拥抱这一解决方案,企业可以更从容地应对数据洪流,深入挖掘数据金矿,最终在数字化浪潮中赢得先机,实现可持续的增长与创新。